Это руководство проведет вас через процесс работы с Node.js и популярными пакетами CheerioJS и Puppeteer . Проработав примеры, вы узнаете все советы и рекомендации, которые вам понадобятся, чтобы научиться использовать Node.js в сборе любых данных.
Мы будем собирать список всех имен и дней рождения президентов США из Википедии, а также названия всех сообщений на первой странице Reddit.
Начнем с установки библиотек, которые мы будем использовать (установка Puppeteer займет некоторое время, так как ему также необходимо загрузить Chromium).
npm install --save request request-promise cheerio puppeteerЗатем давайте откроем новый текстовый файл (назовите файл potusScraper.js) и напишем быструю функцию для получения HTML-кода страницы «Список президентов» Википедии.
const rp = require('request-promise');
const url = 'https://en.wikipedia.org/wiki/List_of_Presidents_of_the_United_States';
rp(url)
.then(function(html){
//success!
console.log(html);
})
.catch(function(err){
//handle error
});Получили:
<!DOCTYPE html>
<html class="client-nojs" lang="en" dir="ltr">
<head>
<meta charset="UTF-8"/>
<title>List of Presidents of the United States - Wikipedia</title>
...Использование Chrome DevTools
Мы получили необработанный HTML с веб-страницы! Но теперь нам нужно разобраться в этом гигантском куске текста. Для этого нам нужно использовать Chrome DevTools, чтобы мы могли легко искать в HTML-коде веб-страницы.
Использовать Chrome DevTools просто: откройте Google Chrome и щелкните правой кнопкой мыши элемент, который вы хотите очистить (в данном случае я щелкаю правой кнопкой мыши Джорджа Вашингтона, потому что мы хотим получить ссылки на все страницы Википедии отдельных президентов) :
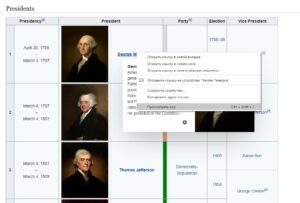
Теперь просто нажмите кнопку «Проверить», и Chrome откроет панель инструментов DevTools, позволяющую легко проверить исходный HTML-код страницы.
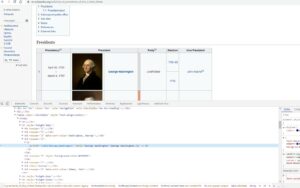
Разбор HTML с Cheerio.js
Замечательно, Chrome DevTools теперь показывает нам точный шаблон, который мы должны искать в коде («b» тег с гиперссылкой внутри). Давайте воспользуемся Cheerio.js для анализа полученного ранее HTML и вернем список ссылок на отдельные страницы Википедии президентов США.
const rp = require('request-promise');
const $ = require('cheerio');
const url = 'https://en.wikipedia.org/wiki/List_of_Presidents_of_the_United_States';
rp(url)
.then(function(html){
//success!
console.log($('td > b > a', html).length);
console.log($('td > b > a', html));
})
.catch(function(err){
//handle error
});Получили:
45
{ '0':
{ type: 'tag',
name: 'a',
attribs: { href: '/wiki/George_Washington', title: 'George Washington' },
children: [ [Object] ],
next: null,
prev: null,
parent:
{ type: 'tag',
name: 'big',
attribs: {},
children: [Array],
next: null,
prev: null,
parent: [Object] } },
'1':
{ type: 'tag'
...Мы проверяем, что возвращено ровно 45 элементов (количество президентов США на момент написания статьи), что означает отсутствие каких-либо дополнительных скрытых «больших» тегов где-либо еще на странице. Теперь мы можем пройти и получить список ссылок на все 45 президентских страниц Википедии, взяв их из раздела «атрибуты» каждого элемента.
const rp = require('request-promise');
const $ = require('cheerio');
const url = 'https://en.wikipedia.org/wiki/List_of_Presidents_of_the_United_States';
rp(url)
.then(function(html){
//success!
const wikiUrls = [];
for (let i = 0; i < 45; i++) {
wikiUrls.push($('td > b > a', html)[i].attribs.href);
}
console.log(wikiUrls);
})
.catch(function(err){
//handle error
});Получили:
[
'/wiki/George_Washington',
'/wiki/John_Adams',
'/wiki/Thomas_Jefferson',
'/wiki/James_Madison',
'/wiki/James_Monroe',
'/wiki/John_Quincy_Adams',
'/wiki/Andrew_Jackson',
...
]Давайте еще раз воспользуемся Chrome DevTools, чтобы найти синтаксис кода, который мы хотим проанализировать, чтобы мы могли извлечь имя и день рождения с помощью Cheerio.js.
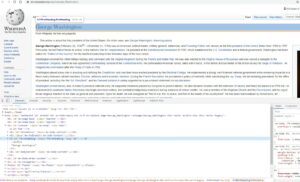
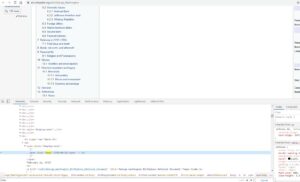
Итак, мы видим, что имя находится в классе с именем «firstHeading», а день рождения — в классе с именем «bday». Давайте изменим наш код, чтобы использовать Cheerio.js для извлечения этих двух классов.
const rp = require('request-promise');
const $ = require('cheerio');
const url = 'https://en.wikipedia.org/wiki/George_Washington';
rp(url)
.then(function(html) {
console.log($('.firstHeading', html).text());
console.log($('.bday', html).text());
})
.catch(function(err) {
//handle error
});Получили:
George Washington
1732-02-22
Собираем все вместе
Теперь превратим это в функцию и экспортируем из модуля.
const rp = require('request-promise');
const $ = require('cheerio');
const potusParse = function(url) {
return rp(url)
.then(function(html) {
return {
name: $('.firstHeading', html).text(),
birthday: $('.bday', html).text(),
};
})
.catch(function(err) {
//handle error
});
};
module.exports = potusParse;Теперь вернемся к нашему исходному файлу potusScraper.js и потребуем модуль potusParse.js. Затем мы применим его к списку wikiUrls, который мы собрали ранее.
const rp = require('request-promise');
const $ = require('cheerio');
const potusParse = require('./potusParse');
const url = 'https://en.wikipedia.org/wiki/List_of_Presidents_of_the_United_States';
rp(url)
.then(function(html) {
//success!
const wikiUrls = [];
for (let i = 0; i < 45; i++) {
wikiUrls.push($('td > b > a', html)[i].attribs.href);
}
return Promise.all(
wikiUrls.map(function(url) {
return potusParse('https://en.wikipedia.org' + url);
})
);
})
.then(function(presidents) {
console.log(presidents);
})
.catch(function(err) {
//handle error
console.log(err);
});Получили:
[
{ name: 'George Washington', birthday: '1732-02-22' },
{ name: 'John Adams', birthday: '1735-10-30' },
{ name: 'Thomas Jefferson', birthday: '1743-04-13' },
{ name: 'James Madison', birthday: '1751-03-16' },
{ name: 'James Monroe', birthday: '1758-04-28' },
{ name: 'John Quincy Adams', birthday: '1767-07-11' },
{ name: 'Andrew Jackson', birthday: '1767-03-15' },
{ name: 'Martin Van Buren', birthday: '1782-12-05' },
{ name: 'William Henry Harrison', birthday: '1773-02-09' },
{ name: 'John Tyler', birthday: '1790-03-29' },
{ name: 'James K. Polk', birthday: '1795-11-02' },
{ name: 'Zachary Taylor', birthday: '1784-11-24' },
{ name: 'Millard Fillmore', birthday: '1800-01-07' },
{ name: 'Franklin Pierce', birthday: '1804-11-23' },
{ name: 'James Buchanan', birthday: '1791-04-23' },
{ name: 'Abraham Lincoln', birthday: '1809-02-12' },
{ name: 'Andrew Johnson', birthday: '1808-12-29' },
{ name: 'Ulysses S. Grant', birthday: '1822-04-27' },
{ name: 'Rutherford B. Hayes', birthday: '1822-10-04' },
{ name: 'James A. Garfield', birthday: '1831-11-19' },
{ name: 'Chester A. Arthur', birthday: '1829-10-05' },
{ name: 'Grover Cleveland', birthday: '1837-03-18' },
{ name: 'Benjamin Harrison', birthday: '1833-08-20' },
{ name: 'Grover Cleveland', birthday: '1837-03-18' },
{ name: 'William McKinley', birthday: '1843-01-29' },
{ name: 'Theodore Roosevelt', birthday: '1858-10-27' },
{ name: 'William Howard Taft', birthday: '1857-09-15' },
{ name: 'Woodrow Wilson', birthday: '1856-12-28' },
{ name: 'Warren G. Harding', birthday: '1865-11-02' },
{ name: 'Calvin Coolidge', birthday: '1872-07-04' },
{ name: 'Herbert Hoover', birthday: '1874-08-10' },
{ name: 'Franklin D. Roosevelt', birthday: '1882-01-30' },
{ name: 'Harry S. Truman', birthday: '1884-05-08' },
{ name: 'Dwight D. Eisenhower', birthday: '1890-10-14' },
{ name: 'John F. Kennedy', birthday: '1917-05-29' },
{ name: 'Lyndon B. Johnson', birthday: '1908-08-27' },
{ name: 'Richard Nixon', birthday: '1913-01-09' },
{ name: 'Gerald Ford', birthday: '1913-07-14' },
{ name: 'Jimmy Carter', birthday: '1924-10-01' },
{ name: 'Ronald Reagan', birthday: '1911-02-06' },
{ name: 'George H. W. Bush', birthday: '1924-06-12' },
{ name: 'Bill Clinton', birthday: '1946-08-19' },
{ name: 'George W. Bush', birthday: '1946-07-06' },
{ name: 'Barack Obama', birthday: '1961-08-04' },
{ name: 'Donald Trump', birthday: '1946-06-14' }
]JavaScript — работа с динамическим контентом
Вуаля! Список имен и дней рождения всех 45 президентов США. Использование только модуля request-promise и Cheerio.js должно помочь работать с подавляющим большинством сайтов в Интернете.
Однако в последнее время многие сайты начали использовать JavaScript для создания динамического контента на своих сайтах. Это вызывает проблему для request-promise и других подобных библиотек HTTP-запросов (таких как axios и fetch), поскольку они получают ответ только от начального запроса, но не могут выполнять JavaScript так, как это может делать веб-браузер. Таким образом, для очистки сайтов, требующих выполнения JavaScript, нам нужно другое решение. Мы будем использовать Puppeteer .
Puppeteer — это чрезвычайно популярный пакет, предложенный командой Google Chrome, который позволяет управлять браузером без головы (headless browser). Это идеально подходит для программного извлечения страниц, требующих выполнения JavaScript. Давайте возьмем HTML-код с главной страницы Reddit, используя Puppeteer вместо request-promise.
const puppeteer = require('puppeteer');
const url = 'https://www.reddit.com';
puppeteer
.launch()
.then(function(browser) {
return browser.newPage();
})
.then(function(page) {
return page.goto(url).then(function() {
return page.content();
});
})
.then(function(html) {
console.log(html);
})
.catch(function(err) {
//handle error
});Страница заполнена правильным контентом!
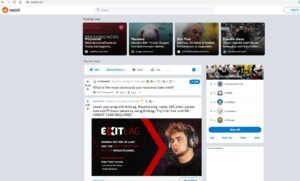
Теперь мы можем использовать Chrome DevTools, как в предыдущем примере. Похоже, что Reddit помещает заголовки в теги «h2». Давайте воспользуемся Cheerio.js для извлечения тегов h2 со страницы.
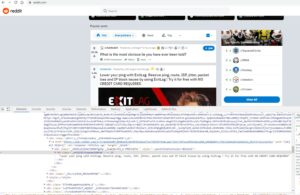
const puppeteer = require('puppeteer');
const $ = require('cheerio');
const url = 'https://www.reddit.com';
puppeteer
.launch()
.then(function(browser) {
return browser.newPage();
})
.then(function(page) {
return page.goto(url).then(function() {
return page.content();
});
})
.then(function(html) {
$('h2', html).each(function() {
console.log($(this).text());
});
})
.catch(function(err) {
//handle error
});Далее вы получите содержимое страницы в тексте, как мы делали это на предыдущих шагах.
Вот мы и написали парсер для сбора данных с любого веб-сайта.
Может быть интересно:
Применить к вашей задаче
Нужны регулярные данные, а не разовая выгрузка?
Покажите список товаров и источников. Проверим доступность данных и предложим структуру первого теста.